Appendix D: Regular expressions
Most FortiWeb features support regular expressions. Regular expressions are a powerful way of denoting all possible forms of a string. They are very useful when trying to match text that comes in many variations but follows a definite pattern, such as dynamic URLs or web page content.
Regular expressions can involve very computationally intensive evaluations. For best performance, you should only use regular expressions where necessary, and build them with care. For information on optimization, see Regular expression performance tips.
See also
Regular expression syntax
Accurate regular expression syntax is vital for detecting different forms of the same attack, for rewriting all but only the intended URLs, and for allowing normal traffic to pass (see Reducing false positives). When configuring Regular Expression or similar settings, always use the >> (test) button to:
- Validate your expression’s syntax.
- Look for unintended matches.
- Verify intended matches.
Will your expression match? Will it match more than once? Where will it match? Generally, unless the feature is specifically designed to look for all instances, FortiWeb will evaluate only a specific location for a match, and it will start from that location’s beginning. (In English, this is the left most, topmost point in the string.) FortiWeb will take only the first match, unless you have defined a number of repetitions.
FortiWeb follows most Perl-compatible regular expression (PCRE) syntax. Popular FortiWeb regular expression syntax shows syntax and popular grammar examples. You can find additional examples with each feature, such as Example: Sanitizing poisoned HTML.

|
Inverse string matching is not currently supported.
For example, to match all strings that do not contain hamsters, you cannot use:
!(hamsters)
You can, however, use inverse matching for specific character classes, such as:
[^A]
to match any string that contains any characters that are not the letter A.
|
Popular FortiWeb regular expression syntax
| Anything except *.|^$?+\(){}[] |
Literal match, except if the character is part of a:
- capture group
- back-reference (e.g. $0 or \1)
- other regular expression token (e.g. \w)
|
Text: My cat catches things.
Regular expression: cat
Matches: cat
Depending on whether the feature looks for all instances, it may also match “cat” in the beginning of “catches”.
|
| \ |
Escape character. If it is followed by:
- An alphanumeric character, the alphanumeric character is not matched literally as usual. Instead, it is interpreted as a regular expression token. For example, \w matches a word, as defined by the locale.
- Any regular expression special character:
*.|^$?+\(){}[]\
this escapes interpretation as a regular expression token, and instead treats it as a normal letter. For example, \\ matches:
\
|
Text: /url?parameter=value
Regular expression: \?param
Matches: ?param
|
| (?i) |
Turns on case-insensitive matching for subsequent evaluation, until it is turned off or the evaluation completes. |
Text: /url?Parameter=value
Regular expression: (?i)param
Matches: Param
Would also match pArAM etc.
|
| \n |
Matches a new line (also called a line feed).
Microsoft Windows platforms typically use \r\n at the end of each line. Linux and Unix platforms typically use \n. Mac OS X typically uses \r
|
Text: My cat catches things.
Regular expression: \n
Matches: The end of the text on Linux and other Unix-like platforms, only part of the line ending on Windows, and nothing on Mac OS X.
|
| \r |
Matches a carriage return. |
Text: My cat catches things.
Regular expression: \r
Matches: Part of the line ending on Windows, nothing on Linux/Unix, and the whole line ending on Mac OS X.
|
| \s |
Matches a space, non-breaking space, tab, line ending, or other white space character.
Tip: Many languages do not separate words with white space. Even in languages that usually use a white space separator, words can be separated with many other characters such as:
\/-”’"“‘.,><—:;
and new lines.
In these cases, you should usually include those in addition to \s in a match set ( [] ) or may need to use \b (word boundary) instead.
|
Text: <a href=‘http://www.example.com’>
Regular expression: www\.example\.com\s
Matches: Nothing.
Due to the final ’ which is a word boundary but not a white space, this does not match. The regular expression should be:
www.example.com\b
|
| \S |
Matches a character that is not white space, such as A or 9. |
Text: My cat catches things.
Regular expression: \S
Matches: Mycatcatchesthings.
|
| \d |
Matches a decimal digit such as 9. |
Text: /url?parameterA=value1
Regular expression: \d
Matches: 1
|
| \D |
Matches a character that is not a digit, such as A or b or É. |
|
| \w |
Matches a whole word.
Words are substrings of any uninterrupted combination of one or more characters from this set:
[a-zA-Z0-9_]
between two word boundaries (space, new line, :, etc.).
It does not match Unicode characters that are equivalent, such as 三, ٣ or 光.
|
Text: Yahoo!
Regular expression: \w
Matches: Yahoo
Does not match the terminal exclamation point, which is a word boundary.
|
| \W |
Matches anything that is not a word. |
Text: Sell?!?~
Regular expression: \W
Matches: ?!?~
|
| . |
Matches any single character except \r or \n.
Note: If the character is written by combining two Unicode code points, such as à where the core letter is encoded separately from the accent mark, this will not match the entire character: it will only match one of the code points.
|
Text: My cat catches things.
Regular expression: c.t
Matches: cat cat
|
| + |
Repeatedly matches the previous character or capture group, 1 or more times, as many times as possible (also called “greedy” matching) unless followed by a question mark ( ? ), which makes it optional.
Does not match if there is not at least 1 instance.
|
Text: www.example.com
Regular expression: w+
Matches: www
Would also match “w”, “ww”, “wwww”, or any number of uninterrupted repetitions of the character “w”.
|
| * |
Repeatedly matches the previous character or capture group, 0 or more times. Depending on its combination with other special characters, this token could be either:
- * — Match as many times as possible (also called “greedy” matching).
- *? — Match as few times as possible (also called “lazy” matching).
|
Text: www.example.com
Regular expression: .*
Matches: www.example.com
All of any text, except line endings (\r and \n).
|
|
Text: www.example.com
Regular expression: (w)*?
Matches: www
Would also match common typos where the “w” was repeated too few or too many times, such as “ww” in w.example.com or “wwww” in wwww.example.com. It would still match, however, if no amount of “w” existed.
|
| ? except when followed by = |
Makes the preceding character or capture group optional (also called “lazy” matching). |
Text: www.example.com
Regular expression: (www\.)?example.com
Matches: www.example.com
Would also match example.com.
|
| ?= |
Looks ahead to see if the next character or capture group matches and evaluate the match based upon them, but does not include those next characters in the returned match string (if any).
This can be useful for back-references where you do not want to include permutations of the final few characters, such as matching “cat” when it is part of “cats” but not when it is part of “catch”.
|
Text: /url?parameter=valuepack
Regular expression: p(?=arameter)
Matches: p, but only in “parameter, not in “pack”, which does not end with “arameter”.
|
| () |
Creates a capture group or sub-pattern for back-reference or to denote order of operations. See also Example: Inserting & deleting body text and What are back-references?. |
Text: /url/app/app/mapp
Regular expression: (/app)*
Matches: /app/app
|
|
Text: /url?paramA=valueA¶mB=valueB
Regular expression: (param)A=(value)A&\0B\1B
Matches: paramA=valueA¶mB=valueB
|
| | |
Matches either the character/capture group before or after the pipe ( | ). |
Text: Host: www.example.com
Regular expression: (\r\n)|\n|\r
Matches: The line ending, regardless of platform.
|
| ^ |
Matches either:
- the position of the beginning of a line (or, in multiline mode, the first line), not the first character itself
- the inverse of a character, but only if
^ is the first character in a character class, such as [^A]
This is useful if you want to match a word, but only when it occurs at the start of the line, or when you want to match anything that is not a specific character.
|
Text: /url?parameter=value
Regular expression: ^/url
Matches: /url, but only if it is at the beginning of the path string. It will not match “/url” in subdirectories.
|
|
Text: /url?parameter=value
Regular expression: [^u]
Matches: /rl?parameter=vale
|
| $ |
Matches the position of the end of a line (or, in multiline mode, the entire string), not the last character itself. |
|
| [] |
Defines a set of characters or capture groups that are acceptable matches.
To define a set via a whole range instead of listing every possible match, separate the first and last character in the range with a hyphen.
Note: Character ranges are matched according to their numerical code point in the encoding. For example, [@-B] matches any UTF-8 code points from 40 to 42 inclusive:
@AB
|
Text: /url?parameter=value1
Regular expression: [012]
Matches: 1
Would also match 0 or 2.
|
|
Text: /url?parameter=valueB
Regular expression: [A-C]
Matches: B
Would also match “A” or “C”. It would not match “b”.
|
| {} |
Quantifies the number of times the previous character or capture group may be repeated continuously.
To define a varying number repetitions, delimit it with a comma.
|
Text: 1234567890
Regular expression: \d{3}
Matches: 123
|
|
Text: www.example.com
Regular expression: w{1,4}
Matches: www
If the string were a typo such as “ww ” or “wwww”, it would also match that.
|
See also
What are back-references?
A back-reference is a regular expression token such as $0 or $1 that refers to whatever part of the text was matched by the capture group in that position within the regular expression.
Back-references are used whenever you want the output/interpretation to resemble the original match: they insert a substring of the original matching text. Like other regular expression features, back-references help to ensure that you do not have to maintain a large, cumbersome list of all possible URL or HTML permutations and their variations or translations when using features such as custom attack signatures, rewriting, or auto-learning.
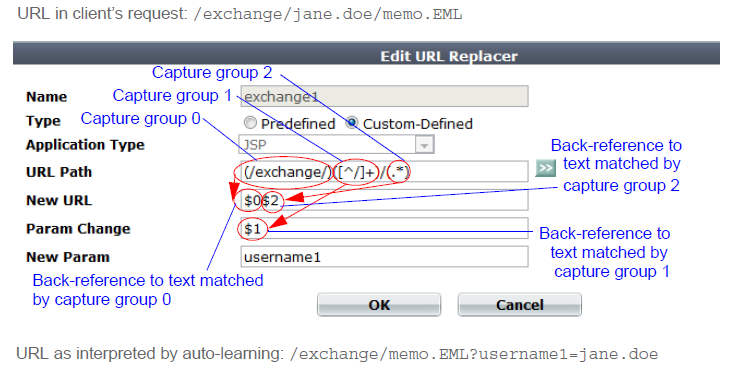
To invoke a substring, use $n (0 <= n <= 9), where n is the order of appearance of capture group in the regular expression, from left to right, from outside to inside, then from top to bottom.
For example, regular expressions in a condition table in this order:
(a)(b)(c(d))(e)
- would result in back-reference variables (e.g.
$0) with the following values:
$0 — a$1 — b$2 — cd$3 — d$4 — e
|
|
Numbering of back-references to capture groups starts from 0: to refer to the first substring, use $0 or /0, not $1 or /1. |
Should you use $0 or /0 to refer back to a substring? Something else? That depends.
/0 — An earlier part in the current string, such as when you have a URL that repeats: (/(^/)*)/0/0/0/0$0 — A part of the previous match string, such as when using part of the originally matched domain name to rewrite the new domain name: $0\.example\.co\.jp where $0 contains www, ftp, or whichever prefix matched the first capture group in the match test regular expression, (^.)*\.example\.com$+ — The highest-numbered capture group of the previous match string: if the capture groups were numbered 0-9, this would be equivalent to /9.$& — The entire match string.
See also
Cookbook regular expressions
Some elements occur often in FortiWeb regular expressions, such as expressions to match domain names, URLs, parameters, and HTML tags. You can use these as building blocks for your own regular expressions.

|
For more expressions to match items such as SQL queries and URIs, see your FortiWeb’s list of predefined data types. |
|
Line endings
(platform-independent)
|
(\r\n)|\n|\r |
|
Any alphanumeric character
(ASCII only; e.g. does not match é or É)
|
[a-zA-Z0-9] |
|
Specific domain name
(e.g. www.example.com; case insensitive)
|
(?i)\bwww\.example\.com\b |
|
Any domain name
(valid non-internationalized TLDs only; does not match domain names surrounded by letters or numbers)
|
(?i)\b.*\.(a(c|d|e(ro)?|f|g|i|m|n|o|q|r|s(ia)?|t|y|w|x|z)|b(a|b|d|e|f|g|h|i(z)?|j|m|n|o|r|s|t|v|w|y|z)|c(a(t)?|c|d|f|g|h|i|k|l|m|n|o((m)?(op)?)|r|s|u|v|x|y|z)|d(e|j|k|m|o|z)|e(c|du|e|g|h|r|s|t|u)|f(i|j|k|m|o|r)|g(a|b|d|e|f|g|h|i|l|m|n|ov|p|q|r|s|t|u|w|y)|h(k|m|n|r|t|u)|i(d|e|l|m|n(fo)?(t)?|o|q|r|s|t)|j(e|m|o(bs)?|p)|k(e|g|h|i|m|n|p|r|w|y|z)|l(a|b|c|i|k|r|s|t|u|vy)|m(a|c|d|e|g|h|il|k|l|m|n|o(bi)?|p|q|r|s|t|u(seum)?|v|w|x|y|z)|n(a(me)?|c|e(t)?|f|g|i|l|o|p|r|u|z)|o(m|rg)|p(a|e|f|g|h|k|l|m|n|r(o)?|s|t|w|y)|qa|r(e|o|s|u|w)|s(a|b|c|d|e|g|h|i|j|k|l|m|n|o|r|s|t|u|v|y|z)|t(c|d|el|f|g|h|j|k|l|m|n|o|p|r(avel)?|t|v|w|z)|u(a|g|k|s|y|z)|v(a|c|e|g|i|n|u)|w(f|s)|xxx|y(e|t|u)|z(a|m|w))\b |
|
Any domain name
(valid internationalized TLDs in UTF-8 only; does not match ASCII-encoded DNS forms such as xn--fiqs8s)
|
(?i)\b.*\.(tél\b|中国|中國|日本|新加坡|ישראל|台灣|الجزائر|বাংলা|مصر|გე|香港|भारत|بھارت|భారత్|ભારત|ਭਾਰਤ|இந்தியா|ভারত|ایران|الاردن|қаз|مليسيا|المغرب|عمان|рф|پاکستان|срб|فلسطين|قطر|சிங்கப்பூர்|السعودية|한국|سوريا|ලංකා|இலங்கை|ไทย|تونس|укр|امارات|台湾|اليمن)\b
|
| Any sub-domain name |
(?i)\b(.*)\.example\.com\b |
| Specific IPv4 address |
\b10\.1\.1\.1\b |
| Any IPv4 address |
\b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b |
|
Specific HTML tag
(well-formed HTML only, e.g. <br> or <img src="1.gif" />; does not match the element’s contents between a tag pair; does not match the closing tag)
|
(?i)<\s*TAG\s*[^>]*> |
|
Specific HTML tag pair and contained text/tags, if any
(well-formed HTML only; expression does not validate by DTD/Schema)
|
(?i)<\s*(TAG)\s*[^>]*>[^<]*</\1> |
|
Any HTML tag pair and contained text/tags, if any
(well-formed HTML only; expression does not validate by DTD/Schema)
|
(?i)<\s*([A-Z][A-Z0-9]*)\b[^>]*>(.*?)</\1>
|
| Any HTML comment |
(?:<|<)!--[\s\S]*?--[ \t\n\r]*(?:>|>) |
|
Any HTML entity
(well-formed entities only; expression does not validate by DTD/Schema)
|
&(?i)(#((x([\dA-F]){1,5})|(104857[0-5]|10485[0-6]\d|1048[0-4]\d\d|104[0-7]\d{3}|10[0-3]\d{4}|0?\d{1,6}))|([A-Za-z\d.]{2,31})); |
|
JavaScript UI events
(onClick(), onMouseOver(), etc.)
|
(?i):on(blur|c(hange|lick)|dblclick|focus|keypress|(key|mouse)(down|up)|(un)?load|mouse(move|o(ut|ver))|reset|s(elect|ubmit)) |
|
All parameters that follow a question mark or hash mark in the URL
(e.g. #pageView or ?param1=valueA¶m2=valueB...; back-reference to this match does not include the question/hash mark itself)
|
[#\?](.*) |
See also
Language support
Features such as Recursive URL Decoding, input rules, and attack signatures can detect attacks and data leaks even when multiple languages are used as an evasion technique.
When configuring FortiWeb, regardless of the display language (see Global web UI & CLI settings), the simplest case is to configure with only US-ASCII characters. All features, including queries to external servers, support it.
If you want to configure FortiWeb using another language/encoding, or support clients using another language or multiple languages, sometimes characters such as ñ, é, symbols, and ideographs such as 新 are valid input. Support varies by the nature of the item being configured.
For example, by definition, host names cannot contain special characters. DNS standards predate many standards for internationalization. Because of this, the web UI and CLI will reject input if it contains non-ASCII encoded characters when configuring the host name. This means that languages other than English are not supported unless encoded as an RFC 3490 international domain name (IDN) prefixed with xn--. However, other configuration items, such as names and comments, often support the language of your choice.
To use your preferred languages in those cases, use an encoding that supports it.
For best results:
- for regular expressions that must match HTTP requests, use the same encoding as your HTTP clients
- for other features, use UTF-8 encoding, or use only the characters whose encoded values are the same in UTF‑8 (for example, US-ASCII characters are usually encoded using the same byte-wise values in ISO 8859-1, Windows code page 1252, Shift-JIS and others; however, ideographs such as 新 may be garbled or interpreted as the wrong character when viewed as another encoding)
|
|
HTTP clients may send requests in encodings that are not UTF-8. Encodings vary by the client’s operating system or input language.
If you input the configuration in English, the client’s request may match regardless of encoding: due to US-ASCII predating most other encodings, byte-wise, the values for English characters tend to have identical numerical values in many encoding types. For example, English words may be readable regardless of interpreting a web page as either ISO 8859-1 or as GB2312.
For other languages (especially non-Latin alphabets such as Cyrillic and Thai), match the client’s encoding exactly.
|
For example, with Shift-JIS, backslashes ( \ ) could be inadvertently interpreted as yen symbols ( ¥ ) and vice versa. A regular expression intended to match HTTP requests containing money values with a yen symbol therefore may not work if the symbol is entered using the wrong encoding. Likewise, simplified Chinese characters might only be understandable if the page is interpreted as GB2312. Test your expressions. If you enter a regular expression using another encoding, or if an HTTP client sends a request in an encoding other than UTF‑8, remember that matches may not be what you initially expect.
Regular expressions are especially impacted. Matching engines on FortiWeb use the UTF‑8 character values. If you need to match multiple possible languages from clients, especially for attack signatures, make sure you construct a regular expression that matches all alternative values.
For example, the Latin letter C is not encoded using the same byte-wise value as the similar-looking Cyrillic letter С. A human being can read a Spanish phrase written with that Cyrillic character, because they are visually similar. But a regular expressions will not match unless written to match both numerical values: one for the Latin character, and one for the Cyrillic look-alike (sometimes called a “confusable”).
To configure your FortiWeb appliance using other encodings, you may need to switch language settings on your management computer, including for your web browser or Telnet/SSH client. For instructions on how to configure your management computer’s operating system language, locale, or input method, see its documentation.
|
|
If you choose to configure parts of the FortiWeb appliance using non-ASCII characters, you should also use the same encoding throughout the configuration if possible in order to avoid needing to switch the language settings of your web browser or Telnet/SSH client while you work.
Similarly, your web browser or CLI client should usually interpret display output as encoded using UTF-8. If it does not, your configured items may not display correctly in the web UI or CLI. Exceptions include items such as regular expressions that you may have configured using other encodings in order to match the encoding of HTTP requests that the FortiWeb appliance receives.
|
See also
Open topic with navigation