Figure 26: Redirecting HTTP to HTTPS (literal string)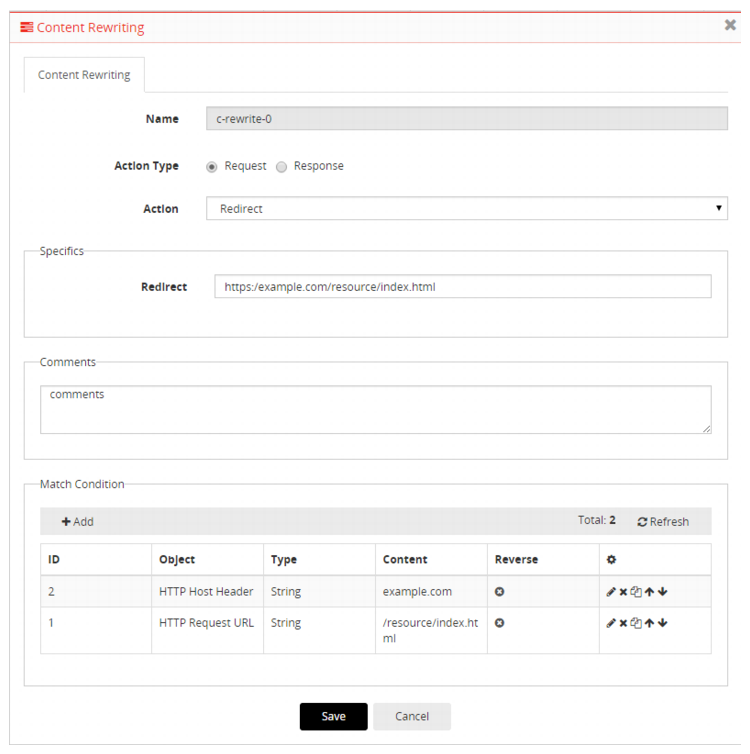
Regular expressions can involve very computationally intensive evaluations. For best performance, you should only use regular expressions where necessary, and build them with care. |
Pattern | Usage | Example |
() | Creates a capture group or sub-pattern for back-reference or to denote order of operations. | Text: /url/app/app/mapp Regular expression: (/app)* Matches: /app/app Text: /url?paramA=valueA¶mB=valueB Regular expression: (param)A=(value)A&\0B\1B Matches: paramA=valueA¶mB=valueB |
$0, $1, $2, ... | Only $0, $1,..., $9 are supported. A back-reference is a regular expression token such as $0 or $1 that refers to whatever part of the text was matched by the capture group in that position within the regular expression. Back-references are used whenever you want the output/interpretation to resemble the original match: they insert a substring of the original matching text. Like other regular expression features, back-references help to ensure that you do not have to maintain a large, cumbersome list of all possible URLs. To invoke a substring, use $n (0 <= n <= 9), where n is the order of appearance of capture group in the regular expression, from left to right, from outside to inside, then from top to bottom. | Let’s say the regular expressions in a condition table have the following capture groups: (a)(b)(c(d))(e) This syntax results in back-reference variables with the following values: • $0 — a • $1 — b • $2 — cd • $3 — d • $4 — e |
\ | Escape character. Except, if it is followed by an alphanumeric character, the alphanumeric character is not matched literally as usual. Instead, it is interpreted as a regular expression token. For example, \w matches a word, as defined by the locale. Except, if it is followed by regular expression special character: *.|^$?+\(){}[]\ When this is the case, the \ escapes interpretation as a regular expression token, and instead treats the character as a normal letter. For example, \\ matches the \ character. | Text: /url?parameter=value Regular expression: \?param Matches: ?param |
. | Matches any single character except \r or \n. Note: If the character is written by combining two Unicode code points, such as à where the core letter is encoded separately from the accent mark, this will not match the entire character: it will only match one of the code points. | Text: My cat catches things. Regular expression: c.t Matches: cat cat |
+ | Repeatedly matches the previous character or capture group, 1 or more times, as many times as possible (also called “greedy” matching) unless followed by a question mark ( ? ), which makes it optional. Does not match if there is not at least 1 instance. | Text: www.example.com Regular expression: w+ Matches: www Would also match “w”, “ww”, “wwww”, or any number of uninterrupted repetitions of the character “w”. |
* | Repeatedly matches the previous character or capture group, 0 or more times. Depending on its combination with other special characters, this token could be either: • * — Match as many times as possible (also called “greedy” matching). • *? — Match as few times as possible (also called “lazy” matching). | Text: www.example.com Regular expression: .* Matches: www.example.com All of any text, except line endings (\r and \n). Text: www.example.com Regular expression: (w)*? Matches: www Would also match common typos where the “w” was repeated too few or too many times, such as “ww” in w.example.com or “wwww” in wwww.example.com. It would still match, however, if no amount of “w” existed. |
? | Makes the preceding character or capture group optional (also called “lazy” matching). This character has a different significance when followed by =. | Text: www.example.com Regular expression: (www\.)?example.com Matches: www.example.com Would also match example.com. |
?= | Looks ahead to see if the next character or capture group matches and evaluate the match based upon them, but does not include those next characters in the returned match string (if any). This can be useful for back-references where you do not want to include permutations of the final few characters, such as matching “cat” when it is part of “cats” but not when it is part of “catch”. | Text: /url?parameter=valuepack Regular expression: p(?=arameter) Matches: p, but only in “parameter, not in “pack”, which does not end with “arameter”. |
^ | Matches either: • the position of the beginning of a line (or, in multiline mode, the first line), not the first character itself • the inverse of a character, but only if ^ is the first character in a character class, such as [^A] This is useful if you want to match a word, but only when it occurs at the start of the line, or when you want to match anything that is not a specific character. | Text: /url?parameter=value Regular expression: ^/url Matches: /url, but only if it is at the beginning of the path string. It will not match “/url” in subdirectories. Text: /url?parameter=value Regular expression: [^u] Matches: /rl?parameter=value |
$ | Matches the position of the end of a line (or, in multiline mode, the entire string), not the last character itself. | |
[] | Defines a set of characters or capture groups that are acceptable matches. To define a set via a whole range instead of listing every possible match, separate the first and last character in the range with a hyphen. Note: Character ranges are matched according to their numerical code point in the encoding. For example, [@-B] matches any UTF-8 code points from 40 to 42 inclusive: @AB | Text: /url?parameter=value1 Regular expression: [012] Matches: 1 Would also match 0 or 2. Text: /url?parameter=valueB Regular expression: [A-C] Matches: B Would also match “A” or “C”. It would not match “b”. |
{} | Quantifies the number of times the previous character or capture group may be repeated continuously. To define a varying number repetitions, delimit it with a comma. | Text: 1234567890 Regular expression: \d{3} Matches: 123 Text: www.example.com Regular expression: w{1,4} Matches: www If the string were a typo such as “ww ” or “wwww”, it would also match that. |
(?i) | Turns on case-insensitive matching for subsequent evaluation, until it is turned off or the evaluation completes. | Text: /url?Parameter=value Regular expression: (?i)param Matches: Param Would also match pArAM etc. |
| | Matches either the character/capture group before or after the pipe ( | ). | Text: Host: www.example.com Regular expression: (\r\n)|\n|\r Matches: The line ending, regardless of platform. |
Regular Expression | Usage |
[a-zA-Z0-9] | Any alphanumeric character. ASCII only; e.g. does not match é or É. |
[#\?](.*) | All parameters that follow a question mark or hash mark in the URL. e.g. #pageView or ?param1=valueA¶m2=valueB...; In this expression, the capture group does not include the question mark or hash mark itself. |
\b10\.1\.1\.1\b | A specific IPv4 address. |
\b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?) \.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?) \.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?) \.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?) \b | Any IPv4 address. |
(?i)\b.*\.(a(c|d|e(ro)?|f|g|i|m|n|o|q|r|s(ia)?|t|y|w|x|z)|b(a|b|d|e|f|g|h|i(z)?|j|m|n|o|r|s|t|v|w|y|z)|c(a(t)?|c|d|f|g|h|i|k|l|m|n|o((m)?(op)?)|r|s|u|v|x|y|z)|d(e|j|k|m|o|z)|e(c|du|e|g|h|r|s|t|u)|f(i|j|k|m|o|r)|g(a|b|d|e|f|g|h|i|l|m|n|ov|p|q|r|s|t|u|w|y)|h(k|m|n|r|t|u)|i(d|e|l|m|n(fo)?(t)?|o|q|r|s|t)|j(e|m|o(bs)?|p)|k(e|g|h|i|m|n|p|r|w|y|z)|l(a|b|c|i|k|r|s|t|u|vy)|m(a|c|d|e|g|h|il|k|l|m|n|o(bi)?|p|q|r|s|t|u(seum)?|v|w|x|y|z)|n(a(me)?|c|e(t)?|f|g|i|l|o|p|r|u|z)|o(m|rg)|p(a|e|f|g|h|k|l|m|n|r(o)?|s|t|w|y)|qa|r(e|o|s|u|w)|s(a|b|c|d|e|g|h|i|j|k|l|m|n|o|r|s|t|u|v|y|z)|t(c|d|el|f|g|h|j|k|l|m|n|o|p|r(avel)?|t|v|w|z)|u(a|g|k|s|y|z)|v(a|c|e|g|i|n|u)|w(f|s)|xxx|y(e|t|u)|z(a|m|w))\b | Any domain name. |
(?i)\bwww\.example\.com\b | A specific domain name. |
(?i)\b(.*)\.example\.com\b | Any sub-domain name of example.com. |