Figure 238: Cluster settings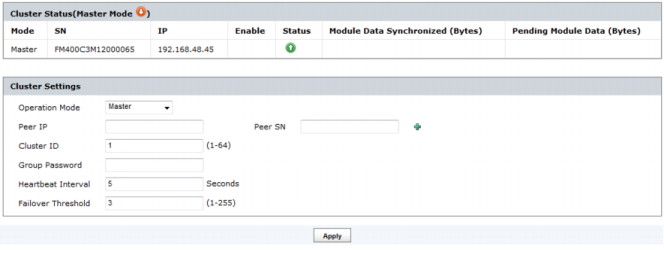
In FortiManager v4.0 MR3, when a HA slave was promoted a reboot was required, This behavior has changed in FortiManager v5.0, so that a reboot is not required when the slave is promoted to master. |
Cluster Status | Monitor FortiManager HA status. See “Monitoring HA status”. | |
Mode | The high availability mode. • Master • Slave | |
SN | The serial number of the device. | |
IP | The IP address of the device. | |
Enable | ||
Status | The status of the cluster member. | |
Module Data Synchronized | Module data synchronized represented in Bytes. | |
Pending Module Data | Pending module data represented in Bytes. | |
Operation Mode | Select Master to configure the FortiManager unit to be the primary unit in a cluster. Select Slave to configure the FortiManager unit to be a backup unit in a cluster. Select Standalone to stop operating in HA mode. | |
Peer IP | Enter the IP address of another FortiManager unit in the cluster. For the primary unit you can add up to five Peer IPs for up to five backup units. For a backup unit you add the IP address of the primary unit. | |
Peer SN | Enter the serial number of another FortiManager unit in the cluster. For the primary unit you can add up to five Peer serial numbers for up to five backup units. For a backup unit you add the serial number of the primary unit. | |
Cluster ID | A number between 0 and 64 that identifies the HA cluster. All members of the HA cluster must have the same group ID. If you have more than one FortiManager HA cluster on the same network, each HA cluster must have a different group ID. The FortiManager Web‑based Manager browser window title changes to include the Group ID when FortiManager unit is operating in HA mode. | |
Group Password | A password for the HA cluster. All members of the HA cluster must have the same group password. The maximum password length is 19 characters. If you have more than one FortiManager HA cluster on the same network, each HA cluster must have a different password. | |
Heartbeat Interval | The time in seconds that a cluster unit waits between sending heartbeat packets. The heartbeat interval is also the amount of time that a FortiManager unit waits before expecting to receive a heartbeat packet from the other cluster unit. The default heartbeat interval is 5 seconds. The heartbeat interval range is 1 to 255 seconds. You cannot configure the heartbeat interval of the backup units. | |
Failover Threshold | The number of heartbeat intervals that one of the cluster units waits to receive HA heartbeat packets from other cluster units before assuming that the other cluster units have failed. The default failover threshold is 3. The failover threshold range is 1 to 255. You cannot configure the failover threshold of the backup units. In most cases you do not have to change the heartbeat interval or failover threshold. The default settings mean that if the a unit fails, the failure is detected after 3 x 5 or 15 seconds; resulting in a failure detection time of 15 seconds. If the failure detection time is too short the HA cluster may detect a failure when none has occurred. For example, if the primary unit is very busy it may not respond to HA heartbeat packets in time. In this situation, the backup unit may assume that the primary unit has failed when the primary unit is actually just busy. Increase the failure detection time to prevent the backup unit from detecting a failure when none has occurred. If the failure detection time is too long, administrators will be delayed in learning that the cluster has failed. In most cases, a relatively long failure detection time will not have a major effect on operations. But if the failure detection time is too long for your network conditions, then you can reduce the heartbeat interval or failover threshold. | |